
 English
EnglishTrần Lương Anh Toán – Tin 03 K68
Khi bạn nhìn một bức ảnh, bạn thấy màu sắc và hình dạng. Nhưng đối với AI, đó chỉ là một mảng dữ liệu khổng lồ chứa hàng triệu con số. Bài viết này sẽ giải mã cách Đại số tuyến tính – thông qua các phép biến đổi không gian và ma trận – đã gọt giũa dữ liệu thô như thế nào để tạo ra đôi mắt cho Trí tuệ nhân tạo.
1. Bức Ảnh Trong Mắt AI Thực Chất Là Gì?

Hãy tưởng tượng bạn đang nhìn vào một bức ảnh chụp một chú mèo. Bạn thấy gì? Một cái đầu tròn, đôi tai nhọn, bộ lông màu cam và một đôi mắt sáng. Quá trình nhận diện này diễn ra trong não bộ con người nhanh đến mức chúng ta coi đó là điều hiển nhiên.
Nhưng đối với Trí tuệ nhân tạo (AI), thế giới không hoạt động như vậy. Máy tính không có giác mạc, cũng không có khái niệm về “lông” hay “tai”. Đối với một mô hình AI, bức ảnh chú mèo kia thực chất chỉ là một khối dữ liệu khổng lồ.
Từ Hình ảnh đến Ma trận
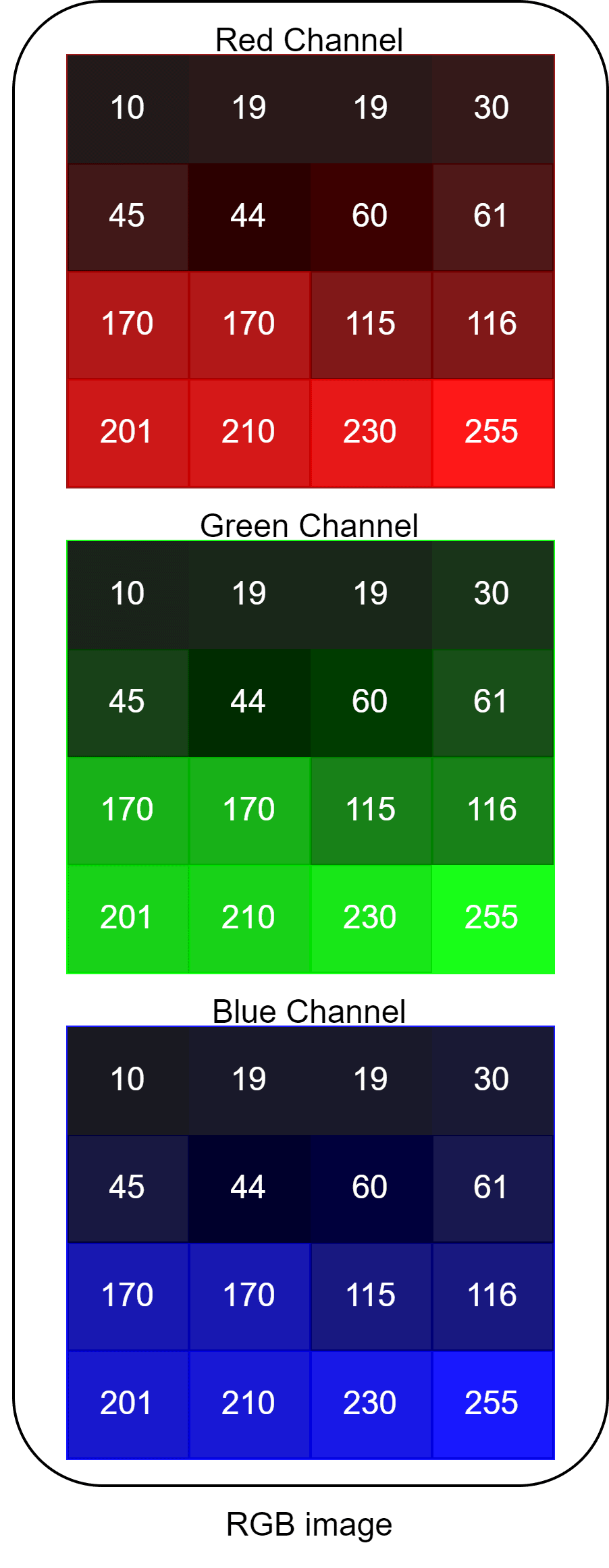
Trong thị giác máy tính (Computer Vision), một bức ảnh không phải là hình ảnh, nó là một Ma trận số.
Để tạo ra màu sắc, hệ thống máy tính sử dụng không gian màu RGB. Điều này có nghĩa là bức ảnh bạn đang xem thực chất là sự chồng chập của 3 ma trận 2 chiều riêng biệt, đại diện cho 3 kênh màu: Đỏ (Red), Xanh lá (Green), và Xanh dương (Blue).
Và một điểm ảnh (pixel) nhỏ xíu trên màn hình thực chất được cấu tạo từ 3 điểm phát sáng phụ (sub-pixels) đại diện cho 3 kênh màu đó.
Tuy nhiên, bên trong bộ nhớ của máy tính, màu sắc không tồn tại. Thay vào đó, máy tính lưu trữ độ sáng của từng màu dưới dạng 3 giá trị số học (thường nằm trong khoảng từ 0 đến 255). Dựa trên nguyên lý hòa trộn ánh sáng, sự kết hợp cường độ của 3 con số này sẽ điều khiển màn hình phát ra hàng triệu sắc độ màu khác nhau.
Về mặt Toán học, màu sắc của một pixel được biểu diễn dưới dạng một vector 3 chiều:
- Một pixel màu đen tuyệt đối sẽ là vector:
[0; 0; 0] - Một pixel màu trắng tinh sẽ là vector:
[255; 255; 255]
Giả sử ta có một bức ảnh màu có kích thước 1,000×1,000 điểm ảnh, khi đưa vào máy tính, sẽ biến thành một khối dữ liệu không gian 3 chiều chứa tới 3 triệu con số! Trong ngôn ngữ Toán học cao cấp và Deep Learning, cấu trúc dữ liệu đa chiều này được gọi là một Tensor.
Sự can thiệp của Đại số tuyến tính
Với 3 triệu con số lộn xộn đó, làm sao AI biết đâu là tai, đâu là mắt mèo? Nếu cứ đưa nguyên khối dữ liệu thô này vào các mạng nơ-ron, máy tính sẽ quá tải và mất phương hướng.
Đó là lúc chúng ta cần “dọn dẹp” dữ liệu. Và công cụ sắc bén nhất, mạnh mẽ nhất mà các kỹ sư AI sử dụng để giải quyết bài toán này không phải là một dòng code tin học phức tạp nào, mà chính là môn học cơ sở quen thuộc của chúng ta: Đại số tuyến tính.
Bằng việc coi bức ảnh là ma trận, chúng ta có thể áp dụng các phép tính đại số để biến đổi màu sắc, nắn chỉnh không gian và tối ưu hóa dòng chảy dữ liệu trước khi đưa cho AI “học”. Ở phần tiếp theo, chúng ta sẽ cùng bóc tách 3 thao tác cốt lõi nhất dưới góc nhìn của Toán học.
2. Thao Tác 1 – Biến Đổi Giá Trị (Phép Nhân Vô Hướng)
Thao tác dọn dẹp dữ liệu đầu tiên và kinh điển nhất trong Thị giác máy tính chính là chuyển đổi ảnh màu sang ảnh xám (Grayscale).

Vậy tại sao lại phải bỏ đi màu sắc? Trong nhiều bài toán nhận diện (như đọc biển số xe, nhận diện chữ viết tay hay trích xuất đường viền vật thể), màu sắc là thông tin dư thừa, thậm chí gây nhiễu. Bằng cách loại bỏ màu sắc, ta giảm khối lượng tính toán của máy tính xuống 3 lần, giúp AI tập trung hoàn toàn vào hình dáng (shape) và độ tương phản của vật thể.
Nhưng câu hỏi đặt ra là: Làm thế nào để toán học ép 3 ma trận màu (Đỏ, Xanh lá, Xanh dương) xẹp xuống thành 1 ma trận duy nhất?
Thuật toán Luminosity Method
Cách đơn giản nhất là lấy trung bình cộng của 3 ma trận. Tuy nhiên, phương pháp này không phản ánh đúng thực tế, vì mắt người nhạy cảm với ánh sáng xanh lá nhất và kém nhạy cảm với ánh sáng xanh dương nhất.
Để khắc phục, các kỹ sư sử dụng Luminosity Method (Phương pháp Độ sáng). Thay vì chia đều, phương pháp này sử dụng các hệ số trọng số cố định: 0.299 cho Đỏ, 0.587 cho Xanh lá, và 0.114 cho Xanh dương. Tổng của 3 con số này đúng bằng 1, đảm bảo bức ảnh không bị sáng lên hay tối đi sau khi biến đổi.
Góc nhìn từ Đại số tuyến tính
Nếu bạn đang học lập trình, bạn sẽ nghĩ đến việc dùng hai vòng lặp for chạy qua hàng triệu pixel để tính toán. Nhưng trong Đại số tuyến tính, tư duy hoàn toàn khác biệt. Mọi thứ được xử lý trên quy mô toàn cục (Matrix-level).
Bản chất của phép chuyển đổi màu này là sự kết hợp của hai phép toán nền tảng: Phép nhân vô hướng (Scalar Multiplication) và Phép cộng ma trận (Matrix Addition)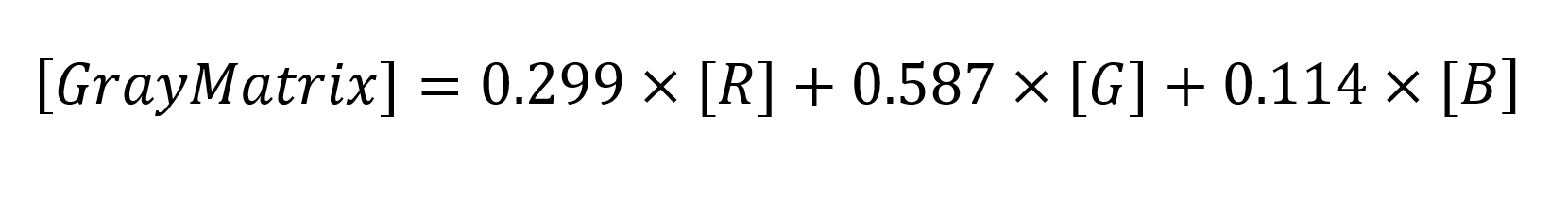
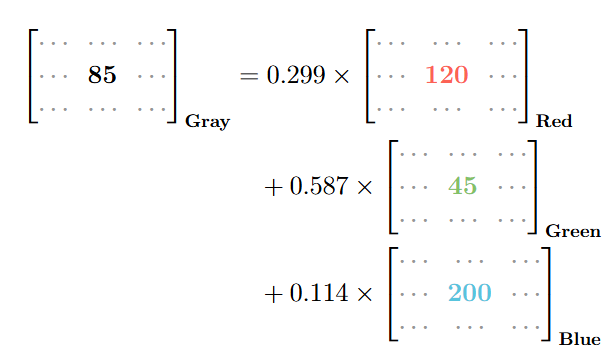
- Với phép cộng ma trận, sau khi đã có 3 ma trận kết quả cùng kích thước, máy tính thực hiện phép cộng các phần tử ở vị trí tương ứng lại với nhau.
- Với Phép nhân vô hướng, máy tính lấy một số thực (ví dụ 0.299) nhân “phân phối” vào từng phần tử bên trong toàn bộ ma trận
[R]. Tương tự cho[G]và[B].
Kết quả cuối cùng đó là lớp ma trận 3 chiều được ép lại tạo thành một ma trận 2 chiều duy nhất chứa cường độ sáng (từ 0 đến 255). Bức ảnh màu đã được chuyển thành ảnh xám một cách hoàn hảo.
Bằng cách sử dụng quy tắc của ma trận thay vì tính toán từng pixel đơn tẻ, máy tính (đặc biệt là GPU) có thể thực hiện hàng triệu phép tính này chỉ trong chớp mắt.
3. Thao Tác 2 – Biến Đổi Không Gian & Ma Trận Affine
Nếu Thao tác 1 can thiệp vào giá trị của điểm ảnh (màu sắc), thì Thao tác 2 sẽ can thiệp vào tọa độ của điểm ảnh đó trong không gian 2D.
Tại sao AI cần biến đổi không gian?
Trong thực tế, camera không bao giờ chụp được một vật thể ở góc độ hoàn hảo. Chú mèo trong ảnh có thể đang nghiêng đầu, nằm xa, nằm gần, hoặc nằm lệch sang một bên. Nếu không nắn chỉnh lại không gian, AI sẽ bối rối và nhận diện sai. Quá trình tạo ra hàng nghìn phiên bản xoay, nghiêng, lật của một bức ảnh gốc để dạy cho AI được gọi là Data Augmentation (Tăng cường dữ liệu).
Và trọng tâm của kỹ thuật này chính là các phép nhân ma trận tọa độ.
Phép biến đổi tuyến tính (Linear Transformation) 2×2
Mỗi pixel trên ảnh đều có một tọa độ (x, y). Để thay đổi hình dáng bức ảnh, ta sẽ nhân tọa độ này với một ma trận biến đổi 2×2:
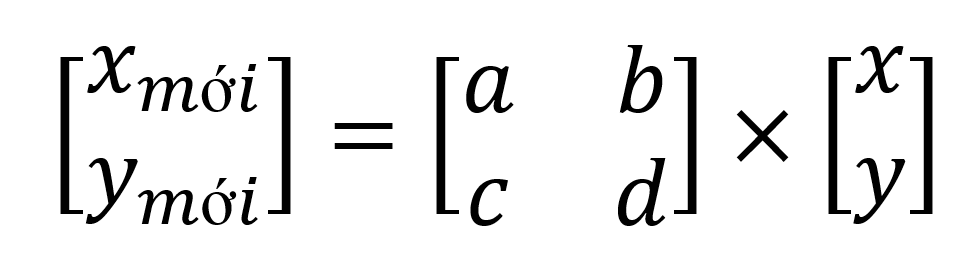
Và khi tác động vào 4 thành phần a, b, c, d này, ta sẽ có được những thao tác gồm:
- Co giãn (Scaling): Tăng giá trị của a và d, bức ảnh sẽ phình to ra hoặc thu nhỏ lại, đồng thời có thể lật ngược ảnh nếu giá trị điền là âm.
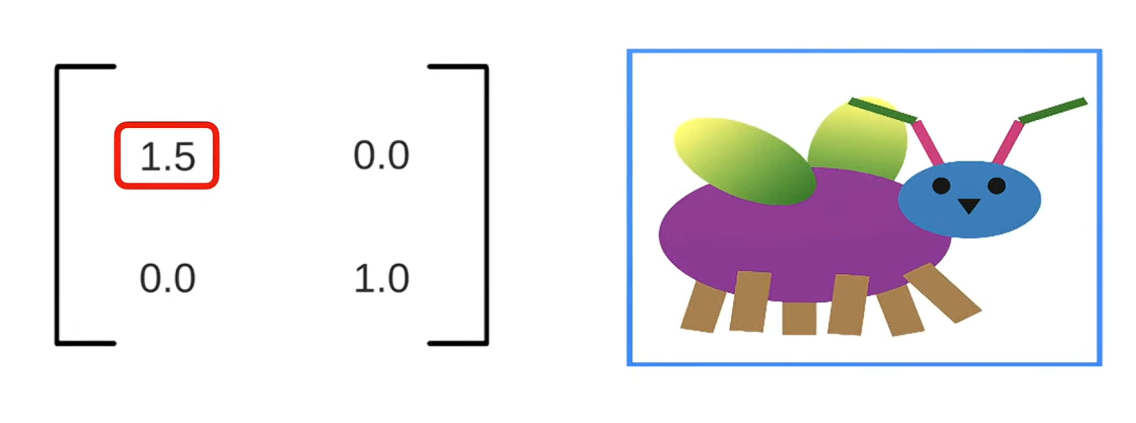
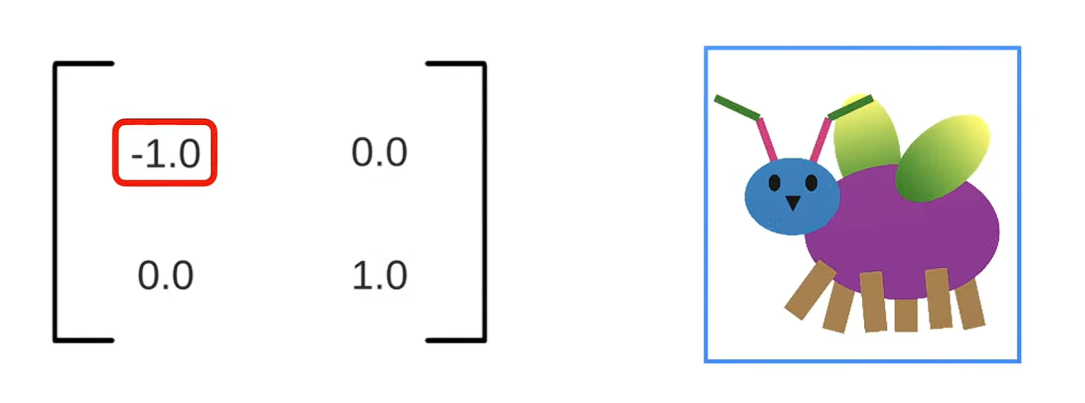
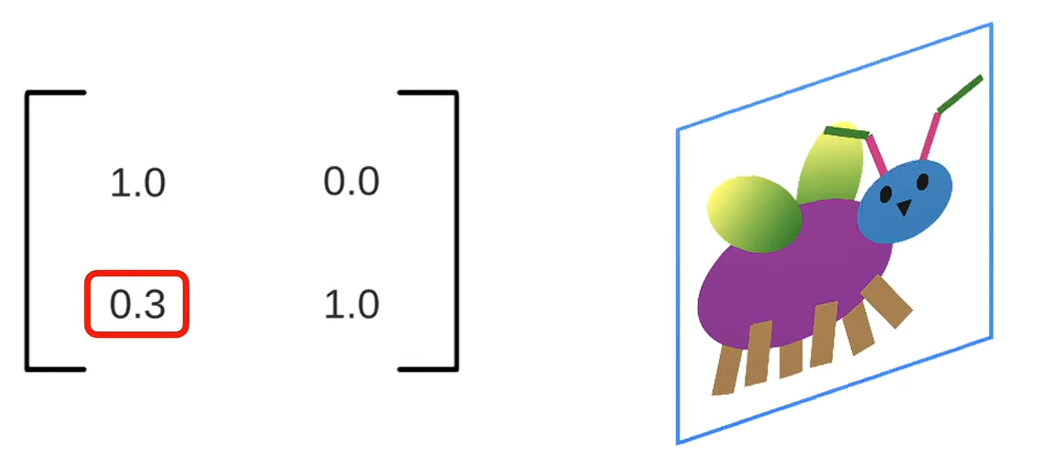
- Biến dạng (Shearing): Thay đổi giá trị của b và c, bức ảnh lập tức bị xô lệch thành hình bình hành, giống như ta đang đẩy nghiêng một khung tranh.
- Xoay (Rotation): Để bức ảnh xoay tròn mà không bị méo mó, 4 con số này không thể thay đổi ngẫu nhiên. Chúng phải phối hợp nhịp nhàng dựa trên các hàm lượng giác.
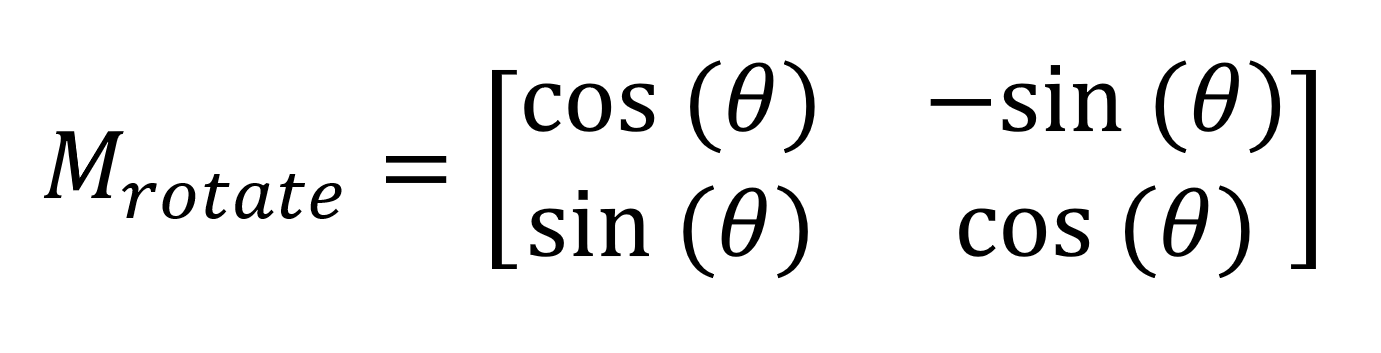
Yếu điểm chí mạng
Tuy nhiên ma trận 2×2 có một yếu điểm chí mạng: Nó tuyệt đối không thể dịch chuyển (tịnh tiến) bức ảnh đi chỗ khác. Lý do rất đơn giản về mặt toán học: Bất kỳ ma trận nào khi nhân với gốc tọa độ (0, 0) thì kết quả vẫn là (0, 0). Tâm của bức ảnh bị “đóng đinh” vĩnh viễn!
Để tịnh tiến bức ảnh, cách duy nhất là dùng phép cộng:
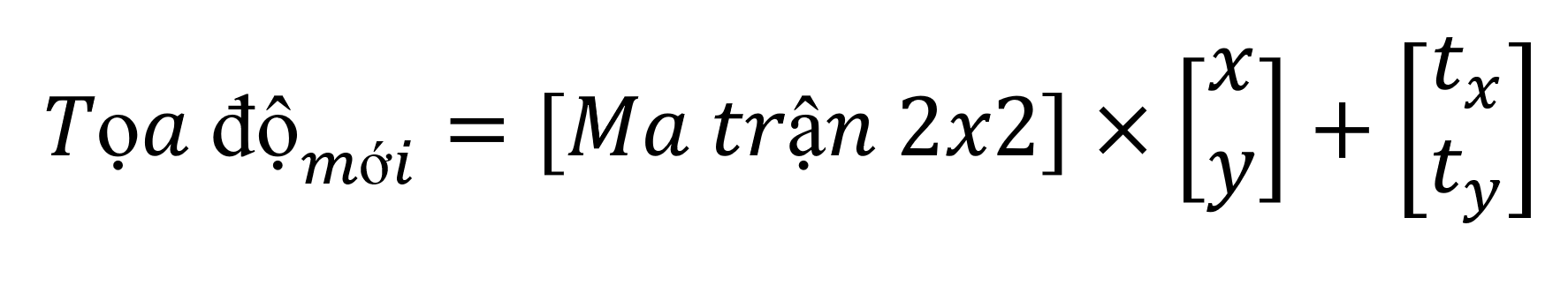
Nhưng máy tính (GPU) được thiết kế để tính toán siêu tốc thông qua MỘT phép nhân ma trận duy nhất. Việc vừa phải làm phép nhân, vừa phải rẽ nhánh sang làm phép cộng sẽ làm giảm hiệu suất xử lý của AI đi rất nhiều.
Để giải quyết, các nhà toán học đã dùng một thủ thuật: Tọa độ đồng nhất (Homogeneous Coordinates). Bằng cách thêm một chiều giả Z = 1 vào tọa độ điểm ảnh, họ đã “nhốt” thành công phép cộng tịnh tiến vào chung một ma trận được gọi là Ma trận Affine 3×3:
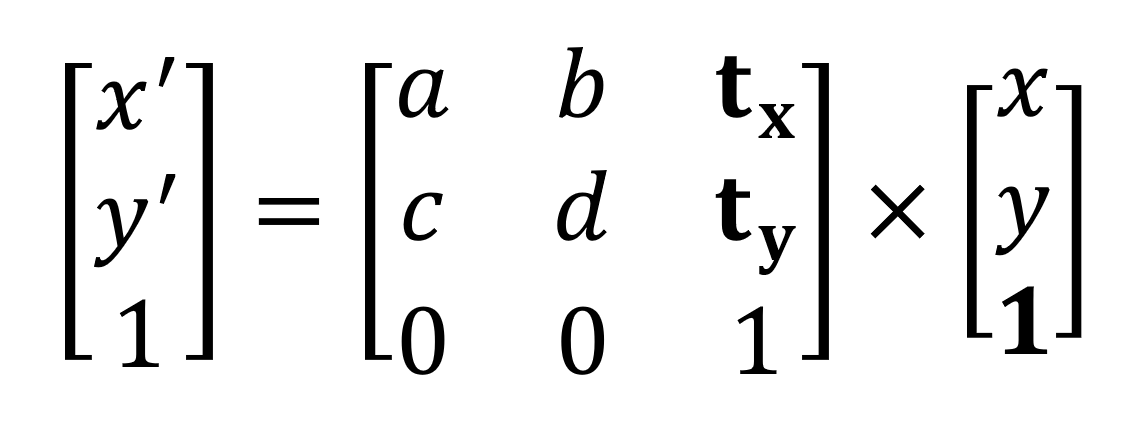
Chỉ bằng cách nâng lên một chiều không gian, Ma trận Affine đã gom trọn vẹn cả 4 thao tác: Co giãn, Biến dạng, Xoay và Tịnh tiến vào trong một phép NHÂN duy nhất. Giờ đây, hàng chục phép biến đổi phức tạp của hàng triệu pixel có thể được máy tính giải quyết chỉ trong một chớp mắt!
4. Thao Tác 3 – Chuẩn Hóa (Normalization) & Giữ Ổn Định Cho AI
Sau khi biến đổi màu sắc và nắn chỉnh không gian, bức ảnh đã sẵn sàng để đi vào bộ não AI. Nhưng trước khi cho AI xử lý, các kỹ sư luôn thực hiện một thao tác bắt buộc: Chuẩn hóa dữ liệu (Normalization).
Để dễ hình dung, hãy tưởng tượng thao tác này giống như việc Quy đổi tiền tệ.
Nếu một ngân hàng muốn phân tích tài chính toàn cầu, họ không thể để nguyên giá trị của Đồng Việt Nam (VND), USD, và Bảng Anh (GBP) để cộng trừ trực tiếp với nhau. Con số của tiền Việt sẽ quá khổng lồ so với tiền Đô, làm sai lệch mọi biểu đồ phân tích. Cách duy nhất là quy đổi tất cả về một đơn vị chung, ví dụ như USD.
Bức ảnh đầu vào của AI cũng vậy. Có những chiếc camera ghi nhận độ sáng từ 0 đến 255 (ảnh 8-bit), nhưng cũng có những camera cao cấp ghi nhận từ 0 đến 1023 (ảnh 10-bit), hay các cảm biến đặc biệt chỉ xuất ra giá trị từ 0 đến 1.
Nếu đưa trực tiếp các ma trận lệch pha này vào mạng nơ-ron, mô hình AI sẽ bị loạn vì các con số quá chênh lệch.
Đưa tất cả về chung một “Hệ quy chiếu”
Để giải quyết, máy tính thực hiện một phép quy đổi “tiền tệ” đơn giản bằng Phép nhân vô hướng: Lấy toàn bộ ma trận ảnh nhân với hệ số 1/255

Mặc dù việc chuyển từ số nguyên sang số thập phân sẽ làm tốn bộ nhớ lưu trữ hơn gấp 4 lần (từ dạng 8-bit sang 32-bit), nhưng đây là cái giá bắt buộc phải trả. Bởi vì:
- Giúp mọi bức ảnh đầu vào, dù chụp bằng thiết bị nào, cũng đều nằm chung trong một “hệ quy chiếu” thập phân từ 0 đến 1.
- Các thuật toán tối ưu của AI (như Gradient Descent) bắt buộc phải tính toán trên các số thực mịn để tìm ra độ dốc, điều mà các số nguyên thô 0 – 255 không thể làm được.
Chỉ bằng một phép nhân vô hướng đơn giản, Đại số tuyến tính đã thiết lập một vạch xuất phát công bằng cho mọi dữ liệu trước khi bước vào cuộc chơi của Trí tuệ nhân tạo.
5. MỞ RỘNG – Từ Toán Học Cơ Sở Đến Học Sâu, Mạng Nơ-Ron
Những phép toán biến đổi ma trận mà chúng ta vừa thảo luận không chỉ dừng lại ở bước “dọn dẹp” dữ liệu thủ công. Trong thế giới thực của Trí tuệ nhân tạo và Học sâu (Deep Learning), chúng chính là nguồn cảm hứng để các nhà khoa học phát minh ra những kiến trúc mạng nơ-ron mạnh mẽ nhất hiện nay.
Từ Biến đổi giá trị đến Lớp Tích Chập (Convolutional Layer)
Trong xử lý ảnh cổ điển, phép chuyển đổi ảnh xám của chúng ta sử dụng bộ số “code cứng” [0.299, 0.587, 0.114] dựa trên mắt người.
Nhưng trong Học máy (Machine Learning), máy tính không cần đến sự áp đặt của con người. Lớp tích chập đầu tiên trong mạng nơ-ron (với các bộ lọc 1×1 Convolution) hoạt động trên cơ chế y hệt như phép biến đổi giá trị màu này. Chỉ có điều, các trọng số không còn cố định. Thông qua quá trình huấn luyện với hàng triệu bức ảnh, AI sẽ tự động “học” xem nên nhân kênh Đỏ với bao nhiêu, kênh Xanh với bao nhiêu để trích xuất được đặc trưng tốt nhất cho bài toán của nó.
Ma trận Affine: Linh hồn của Thuật toán Theo dõi chuyển động
Trong các hệ thống AI tự lái hay camera an ninh giám sát, việc theo dõi vật thể chuyển động (Motion/Object Tracking) theo thời gian thực là một thách thức lớn. Khi một chiếc xe chạy lại gần camera, kích thước của nó to lên (Scale), khi nó rẽ khúc cua, hình dáng của nó bị nghiêng và xoay (Rotate/Shear), và vị trí của nó liên tục thay đổi (Translate).
Để theo dõi chiếc xe một cách liên tục qua từng khung hình, thuật toán AI (như Optical Flow hoặc mạng Spatial Transformer Networks – STN) liên tục tính toán và dự đoán các tham số của Ma trận Affine 3×3. Bằng cách liên tục áp dụng ma trận này lên khung bao (bounding box) của vật thể, AI có thể bám đuổi chiếc xe một cách mượt mà bất chấp mọi sự biến đổi về không gian.
Chuẩn hóa nâng cao & Lớp Chuẩn hóa (Normalization Layers)
Phép nhân vô hướng với 1/255 để đưa dữ liệu về khoảng [0, 1] mới chỉ là mức độ chuẩn hóa cơ bản nhất.
Trong thực tế, các kỹ sư AI thường sử dụng các công thức xác suất để đưa dữ liệu về khoảng [-1, 1] (hoặc dạng phân phối chuẩn có trung bình bằng 0 và độ lệch chuẩn bằng 1 – Z-score Standardization). Việc này giúp dữ liệu có tính đối xứng âm – dương, hỗ trợ các hàm kích hoạt như Tanh hoạt động tối ưu nhất.
Hơn thế nữa, việc chuẩn hóa không chỉ làm một lần ở đầu vào bức ảnh. Khi đi sâu vào hàng chục lớp nơ-ron bên trong mạng, các giá trị số lại tiếp tục bị biến động mạnh. Để giải quyết, các nhà khoa học đã phát minh ra các Lớp chuẩn hóa chuyên dụng như Batch Normalization hay Layer Normalization chèn vào ngay giữa mạng nơ-ron. Chúng liên tục thực hiện phép Z-score để “làm sạch” dữ liệu ngay trong quá trình AI đang học, giúp tốc độ huấn luyện nhanh gấp hàng chục lần.
6. Tổng Kết
Trải qua một hành trình dài từ việc thay đổi sắc độ màu, dịch chuyển không gian bằng ma trận Affine, cho đến phép quy đổi “tiền tệ” số liệu về khoảng an toàn – chúng ta đã cùng nhau chứng kiến một quá trình gọt giũa dữ liệu vô cùng kỳ công.
Nhìn lại toàn bộ những gì đã đi qua, bạn sẽ nhận ra một sự thật thú vị: Mọi phép biến đổi hình ảnh phức tạp nhất thực chất đều được xây dựng từ ba phép toán đại số tuyến tính sơ cấp:
- Nhân ma trận với một số (Scalar Multiplication) – giúp đổi màu và chuẩn hóa biên độ dữ liệu.
- Cộng hai ma trận (Matrix Addition) – giúp xếp chồng các kênh màu và dịch chuyển vật thể.
- Nhân hai ma trận với nhau (Matrix Multiplication) – giúp xoay, co giãn và biến dạng không gian.
Đại số tuyến tính không phải là những trang lý thuyết khô khan nằm lại trên giảng đường. Nó chính là “ngôn ngữ chung” duy nhất giúp chúng ta mã hóa thế giới trực quan sinh động của con người thành một cấu trúc logic hoàn hảo để máy tính có thể bắt đầu quá trình học hỏi.
Bệ phóng tiến vào thế giới Deep Learning
Một bức ảnh thô sau khi được xử lý qua lăng kính của Đại số tuyến tính sẽ không còn là những pixel rời rạc, lộn xộn. Lúc này, nó đã trở thành một khối dữ liệu (Tensor) sạch sẽ, cân bằng và tối ưu. Đây chính là bước đệm quyết định, biến những con số vô tri thành một nguồn tri thức sẵn sàng để các mạng Nơ-ron khai phá.
Khi các phép toán cơ bản đã thiết lập xong một vạch xuất phát chuẩn xác, đó cũng là lúc bộ não AI chính thức vận hành. Ở các tầng sâu hơn bên trong mạng Nơ-ron, máy tính sẽ bắt đầu tự động trích xuất các đặc trưng hình thái để nhận diện thế giới – và đó là lúc các phép toán ma trận nâng cao hơn xuất hiện.
Và lớp đầu tiên mà bức ảnh chuẩn hóa này bước vào chính là Convolutional Layer (Lớp tích chập) – nơi phép Nhân ma trận sẽ vận hành trên cấu trúc trượt của Hình thái học để tạo nên thị giác thực sự cho AI. Nhưng đó sẽ là câu chuyện thú vị của bài viết tiếp theo!
🎥 Video minh họa trực quan
Để củng cố lại các lý thuyết vừa đọc, bạn có thể xem thêm video ngắn trực quan dưới đây về cách Đại số tuyến tính vận hành trong Thị giác máy tính nhé!
▶ Xem Video trên Facebook